Robust approximations of compact sets¶
Claire Brécheteau
https://www.math.sciences.univ-nantes.fr/~brecheteau/
We consider $\mathcal{K}$, an unknown compact subset of the Euclidean space $(\mathbb{R}^d,\|\cdot\|)$. We dispose of a sample of $n$ points $\mathbb{X} = \{X_1, X_2,\ldots, X_n\}$ generated uniformly on $\mathcal{K}$ or generated in a neighborhood of $\mathcal{K}$. The sample of points may be corrupted by outliers. That is, by points lying far from $\mathcal{K}$.
Given $X_1, X_2,\ldots, X_n$, we aim at recovering $\mathcal{K}$. More precisely, we construct approximations of $\mathcal{K}$ as unions of $k$ balls or $k$ ellipsoids, for $k$ possibly much smaller than the sample size $n$.
Note that $\mathcal{K}$ coincides with $d_{\mathcal{K}}^{-1}((-\infty,0])$, the sublevel set of the distance-to-compact function $d_{\mathcal{K}}$. Then, the approximations we propose for $\mathcal{K}$ are sublevel sets of approximations of the distance function $d_{\mathcal{K}}$, based on $\mathbb{X}$. Since the sample may be corrupted by outliers and the points may not lie exactly on the compact set, approximating $d_{\mathcal{K}}$ by $d_{\mathbb{X}}$ may be terrible. Therefore, we construct approximations of $d_{\mathcal{K}}$ that are robust to noise.
In this page, we present three methods to construct approximations of $d_{\mathcal{K}}$ from a possibly noisy sample $\mathbb{X}$. The first approximation is the well-known distance-to-measure (DTM) function of [Chazal11]. The two last methods are new. They are based on the following approximations which sublevel sets are unions of $k$ balls or ellispoids: the $k$-PDTM [Brecheteau19a] and the $k$-PLM [Brecheteau19b].
The codes and some toy examples are available in this page. In particular, they are implemented via the functions:
- DTM(X,query_pts,q)
- kPDTM(X,query_pts,q,k,sig,iter_max = 10,nstart = 1)
- kPLM(X,query_pts,q,k,sig,iter_max = 10,nstart = 1)
For a sample X of size $n$, these functions compute the distance approximations at the points in query_pts. The parameter q is a regularity parameter in $\{0,1,\ldots,n\}$, k is the number of balls or ellispoids for the sublevel sets of the distance approximations. The procedures remove $n-$sig points of the sample, cf Section "Detecting outliers".
Example¶
We consider as a compact set $\mathcal{K}$, the infinity symbol:

The target is the distance function $d_{\mathcal{K}}$. The graph of $-d_{\mathcal{K}}$ is the following:

We have generated a noisy sample $\mathbb X$. Then, $d_{\mathbb X}$ is a terrible approximation of $d_{\mathcal{K}}$. Indeed, the graph of $-d_{\mathbb X}$ is the following:

Nonetheless, there exist robust approximations of the distance-to-compact function, such as the distance-to-measure (DTM) function $d_{\mathbb X,q}$ (that depends on a regularity parameter $q$) [Chazal11]. The graph of $-d_{\mathbb X,q}$ for some $q$ is the following:

In this page, we define two functions, the $k$-PDTM $d_{\mathbb X,q,k}$ and the $k$-PLM $d'_{\mathbb X,q,k}$. The sublevel sets of the $k$-PDTM are unions of $k$ balls. The sublevel sets of the $k$-PLM are unions of $k$ ellipsoids.
The graphs of $-d_{\mathbb X,q,k}$ and $-d'_{\mathbb X,q,k}$ for some $q$ and $k$ are the following:
 and
and 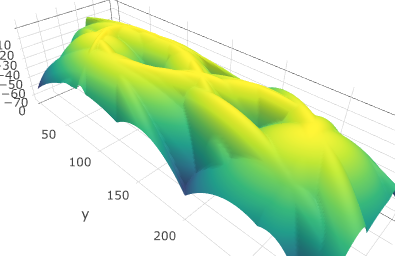
The distance-to-measure (DTM)¶
The distance-to-measure function (DTM) is a surrogate for the distance-to-compact, robust to noise. It was introduced in 2009 [Chazal11]. It depends on some regularity parameter $q\in\{0,1,\ldots,n\}$. The distance-to-measure function $d_{\mathbb{X},q}$ is defined by $$ d_{\mathbb{X},q}^2:x\mapsto \|x-m(x,\mathbb{X},q)\|^2 + v(x,\mathbb{X},q), $$ where $m(x,\mathbb{X},q) = \frac{1}{q}\sum_{i=1}^qX^{(i)}$ is the barycenter of the $q$ nearest neighbours of $x$ in $\mathbb{X}$, $X^{(1)}, X^{(2)},\ldots, X^{(q)}$, and $v(x,\mathbb{X},q)$ is their variance $\frac{1}{q}\sum_{i=1}^q\|m(x,\mathbb{X},q)-X^{(i)}\|^2$.
Equivalently, the DTM coincides with the mean distance between $x$ and its $q$ nearest neighbours: $$d_{\mathbb{X},q}^2(x) = \frac{1}{q}\sum_{i=1}^q\|x-X^{(i)}\|^2.$$
The following implementation of the DTM is due to Raphaël Tinarrage, in his page DTM-based filtrations: demo.
import numpy as np
from sklearn.neighbors import KDTree
def DTM(X,query_pts,q):
'''
Compute the values of the DTM of the point cloud X
Require sklearn.neighbors.KDTree to search nearest neighbors
Input:
X: a nxd numpy array representing n points in R^d
query_pts: a sxd numpy array of query points
q: parameter of the DTM in {1,2,...,n}
Output:
DTM_result: a sx1 numpy array contaning the DTM of the
query points
Example:
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Q = np.array([[0,0],[5,5]])
DTM_values = DTM(X, Q, 3)
'''
n = X.shape[0]
if(q>0 and q<=n):
kdt = KDTree(X, leaf_size=30, metric='euclidean')
NN_Dist, NN = kdt.query(query_pts, q, return_distance=True)
DTM_result = np.sqrt(np.sum(NN_Dist*NN_Dist,axis=1) / q)
else:
raise AssertionError("Error: q should be in {1,2,...,n}")
return(DTM_result)
Example - DTM computation for a noisy sample on a circle¶
The points are generated on the circle accordingly to the following function SampleOnCircle. Again, this whole example was picked from the page DTM-based filtrations: demo of Raphaël Tinarrage.
import matplotlib.pyplot as plt
def SampleOnCircle(N_obs = 100, N_out = 0, is_plot = False):
'''
Sample N_obs points (observations) points from the uniform distribution on the unit circle in R^2,
and N_out points (outliers) from the uniform distribution on the unit square
Input:
N_obs: number of sample points on the circle
N_noise: number of sample points on the square
is_plot = True or False : draw a plot of the sampled points
Output :
data : a (N_obs + N_out)x2 matrix, the sampled points concatenated
'''
rand_uniform = np.random.rand(N_obs)*2-1
X_obs = np.cos(2*np.pi*rand_uniform)
Y_obs = np.sin(2*np.pi*rand_uniform)
X_out = np.random.rand(N_out)*2-1
Y_out = np.random.rand(N_out)*2-1
X = np.concatenate((X_obs, X_out))
Y = np.concatenate((Y_obs, Y_out))
data = np.stack((X,Y)).transpose()
if is_plot:
fig, ax = plt.subplots()
plt_obs = ax.scatter(X_obs, Y_obs, c='tab:cyan');
plt_out = ax.scatter(X_out, Y_out, c='tab:orange');
ax.axis('equal')
ax.set_title(str(N_obs)+'-sampling of the unit circle with '+str(N_out)+' outliers')
ax.legend((plt_obs, plt_out), ('data', 'outliers'), loc='lower left')
return data
' Sampling on the circle with outlier '
N_obs = 150 # number of points sampled on the circle
N_out = 100 # number of outliers
X = SampleOnCircle(N_obs, N_out, is_plot=True) # sample points with outliers

' Compute the DTM on X '
# compute the values of the DTM of parameter q
q = 40
DTM_values = DTM(X,X,q)
# plot of the opposite of the DTM
fig, ax = plt.subplots()
plot=ax.scatter(X[:,0], X[:,1], c=-DTM_values)
fig.colorbar(plot)
ax.axis('equal')
ax.set_title('Values of -DTM on X with parameter q='+str(q));

Approximating $\mathcal{K}$ with a union of $k$ balls - or - the $k$-power-distance-to-measure ($k$-PDTM)¶
The $k$-PDTM is an approximation of the DTM, which sublevel sets are unions of $k$ balls. It was introduced and studied in [Brecheteau19a].
According to the previous expression of the DTM, the DTM rewrites as <a id = #deuxieme_expressionDTM> $$d{\mathbb{X},q}^2:x\mapsto \inf{c\in\mathbb{R}^d}|x-m(c,\mathbb X,q)|^2+v(c,\mathbb X,q).$$ </a> The $k$-PDTM $d{\mathbb{X},q,k}$ is an approximation of the DTM that consists in replacing the infimum over $\mathbb{R}^d$ in [this new formula ](#deuxieme_expression_DTM) with an infimum over a set of $k$ centers $c^_1,c^_2,\ldots,c^k$: $$d{\mathbb{X},q,k}^2:x\mapsto \min_{i\in{1,2,\ldots,k}}|x-m(c^_i,\mathbb X,q)|^2+v(c^*_i,\mathbb X,q).$$
These centers are chosen such that the criterion $$ R: (c_1,c_2,\ldots,c_k) \mapsto \sum_{X\in\mathbb X}\min_{i\in\{1,2,\ldots,k\}}\|X-m(c_i,\mathbb X,q)\|^2+v(c_i,\mathbb X,q) $$ is minimal.
Note that these centers $c^*_1,c^*_2,\ldots,c^*_k$ are not necessarily uniquely defined. The following algorithm provides local minimisers of the criterion $R$.
def mean_var(X,x,q,kdt):
'''
An auxiliary function.
Input:
X: an nxd numpy array representing n points in R^d
x: an sxd numpy array representing s points,
for each of these points we compute the mean and variance of the nearest neighbors in X
q: parameter of the DTM in {1,2,...,n} - number of nearest neighbors to consider
kdt: a KDtree obtained from X via the expression KDTree(X, leaf_size=30, metric='euclidean')
Output:
Mean: an sxd numpy array containing the means of nearest neighbors
Var: an sx1 numpy array containing the variances of nearest neighbors
Example:
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
x = np.array([[2,3],[0,0]])
kdt = KDTree(X, leaf_size=30, metric='euclidean')
Mean, Var = mean_var(X,x,2,kdt)
'''
NN = kdt.query(x, q, return_distance=False)
Mean = np.zeros((x.shape[0],x.shape[1]))
Var = np.zeros(x.shape[0])
for i in range(x.shape[0]):
Mean[i,:] = np.mean(X[NN[i],:],axis = 0)
Var[i] = np.mean(np.sum((X[NN[i],:] - Mean[i,:])*(X[NN[i],:] - Mean[i,:]),axis = 1))
return Mean, Var
import random # For the random centers from which the algorithm starts
def optima_for_kPDTM(X,q,k,sig,iter_max = 10,nstart = 1):
'''
Compute local optimal centers for the k-PDTM-criterion $R$ for the point cloud X
Require sklearn.neighbors.KDTree to search nearest neighbors
Input:
X: an nxd numpy array representing n points in R^d
query_pts: an sxd numpy array of query points
q: parameter of the DTM in {1,2,...,n}
k: number of centers
sig: number of sample points that the algorithm keeps (the other ones are considered as outliers -- cf section "Detecting outliers")
iter_max : maximum number of iterations for the optimisation algorithm
nstart : number of starts for the optimisation algorithm
Output:
centers: a kxd numpy array contaning the optimal centers c^*_i computed by the algorithm
means: a kxd numpy array containing the local centers m(c^*_i,\mathbb X,q)
variances: a kx1 numpy array containing the local variances v(c^*_i,\mathbb X,q)
colors: a size n numpy array containing the colors of the sample points in X
points in the same weighted Voronoi cell (with centers in opt_means and weights in opt_variances)
have the same color
cost: the mean, for the "sig" points X[j,] considered as signal, of their smallest weighted distance to a center in "centers"
that is, min_i\|X[j,]-means[i,]\|^2+variances[i].
Example:
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
sig = X.shape[0] # There is no trimming, all sample points are assigned to a cluster
centers, means, variances, colors, cost = optima_for_kPDTM(X, 3, 2, sig)
'''
n = X.shape[0]
d = X.shape[1]
opt_cost = np.inf
opt_centers = np.zeros([k,d])
opt_colors = np.zeros(n)
opt_kept_centers = np.zeros(k)
if(q<=0 or q>n):
raise AssertionError("Error: q should be in {1,2,...,n}")
elif(k<=0 or k>n):
raise AssertionError("Error: k should be in {1,2,...,n}")
else:
kdt = KDTree(X, leaf_size=30, metric='euclidean')
for starts in range(nstart):
# Initialisation
colors = np.zeros(n)
min_distance = np.zeros(n) # Weighted distance between a point and its nearest center
kept_centers = np.ones((k), dtype=bool)
first_centers_ind = random.sample(range(n), k) # Indices of the centers from which the algorithm starts
centers = X[first_centers_ind,:]
old_centers = np.ones([k,d])*np.inf
mv = mean_var(X,centers,q,kdt)
Nstep = 1
while((np.sum(old_centers!=centers)>0) and (Nstep <= iter_max)):
Nstep = Nstep + 1
# Step 1: Update colors and min_distance
for j in range(n):
cost = np.inf
best_ind = 0
for i in range(k):
if(kept_centers[i]):
newcost = np.sum((X[j,:] - mv[0][i,:])*(X[j,:] - mv[0][i,:])) + mv[1][i]
if(newcost < cost):
cost = newcost
best_ind = i
colors[j] = best_ind
min_distance[j] = cost
# Step 2: Trimming step - Put color -1 to the (n-sig) points with largest cost
index = np.argsort(-min_distance)
colors[index[range(n-sig)]] = -1
ds = min_distance[index[range(n-sig,n)]]
costt = np.mean(ds)
# Step 3: Update Centers and mv
old_centers = np.copy(centers)
old_mv = mv
for i in range(k):
pointcloud_size = np.sum(colors == i)
if(pointcloud_size>=1):
centers[i,] = np.mean(X[colors==i,],axis = 0)
else:
kept_centers[i] = False
mv = mean_var(X,centers,q,kdt)
if(costt <= opt_cost):
opt_cost = costt
opt_centers = np.copy(old_centers)
opt_mv = old_mv
opt_colors = np.copy(colors)
opt_kept_centers = np.copy(kept_centers)
centers = opt_centers[opt_kept_centers,]
means = opt_mv[0][opt_kept_centers,]
variances = opt_mv[1][opt_kept_centers]
colors = np.zeros(n)
for i in range(n):
colors[i] = np.sum(opt_kept_centers[range(int(opt_colors[i]+1))])-1
cost = opt_cost
return(centers, means, variances, colors, cost)
def kPDTM(X,query_pts,q,k,sig,iter_max = 10,nstart = 1):
'''
Compute the values of the k-PDTM of the empirical measure of a point cloud X
Require sklearn.neighbors.KDTree to search nearest neighbors
Input:
X: a nxd numpy array representing n points in R^d
query_pts: a sxd numpy array of query points
q: parameter of the DTM in {1,2,...,n}
k: number of centers
sig: number of points considered as signal in the sample (other signal points are trimmed)
Output:
kPDTM_result: a sx1 numpy array contaning the kPDTM of the
query points
Example:
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Q = np.array([[0,0],[5,5]])
kPDTM_values = kPDTM(X, Q, 3, 2,X.shape[0])
'''
n = X.shape[0]
if(q<=0 or q>n):
raise AssertionError("Error: q should be in {1,2,...,n}")
elif(k<=0 or k>n):
raise AssertionError("Error: k should be in {1,2,...,n}")
elif(X.shape[1]!=query_pts.shape[1]):
raise AssertionError("Error: X and query_pts should contain points with the same number of coordinates.")
else:
centers, means, variances, colors, cost = optima_for_kPDTM(X,q,k,sig,iter_max = iter_max,nstart = nstart)
kPDTM_result = np.zeros(query_pts.shape[0])
for i in range(query_pts.shape[0]):
kPDTM_result[i] = np.inf
for j in range(means.shape[0]):
aux = np.sqrt(np.sum((query_pts[i,]-means[j,])*(query_pts[i,]-means[j,]))+variances[j])
if(aux<kPDTM_result[i]):
kPDTM_result[i] = aux
return(kPDTM_result, centers, means, variances, colors, cost)
We compute the $k$-PDTM on the same sample of points.
Note that when we take $k=250$, that is, when $k$ is equal to the sample size, the DTM and the $k$-PDTM coincide on the points of the sample.
The sub-level sets of the $k$-PDTM are unions of $k$ balls which centers are represented by triangles.
' Compute the k-PDTM on X '
# compute the values of the DTM of parameter q
q = 40
k = 250
sig = X.shape[0]
iter_max = 100
nstart = 10
kPDTM_values, centers, means, variances, colors, cost = kPDTM(X,X,q,k,sig,iter_max,nstart)
# plot of the opposite of the DTM
fig, ax = plt.subplots()
plot = ax.scatter(X[:,0], X[:,1], c=-kPDTM_values)
fig.colorbar(plot)
for i in range(means.shape[0]):
ax.scatter(means[i,0],means[i,1],c = "black",marker = "^")
ax.axis('equal')
ax.set_title('Values of -kPDTM on X with parameter q='+str(q)+' and k='+str(k)+'.');

Approximating $\mathcal{K}$ with a union of $k$ ellipsoids - or - the $k$-power-likelihood-to-measure ($k$-PLM)¶
Sublevel sets of the $k$-PDTM are unions of $k$ balls. The $k$-PLM is a generalisation of the $k$-PDTM. Its sublevel sets are unions of $k$ ellipsoids. It was introduced and studied in [Brecheteau19b].
The $k$-PLM $d'_{\mathbb{X},q,k}$ is defined from a set of $k$ centers $c^*_1,c^*_2,\ldots,c^*_k$ and a set of $k$ covariance matrices $\Sigma^*_1,\Sigma^*_2,\ldots,\Sigma^*_k$ by $${d'}_{\mathbb{X},q,k}^2:x\mapsto \min_{i\in\{1,2,\ldots,k\}}\|x-m(c^*_i,\mathbb X,q,\Sigma^*_i)\|_{\Sigma^*_i}^2+v(c^*_i,\mathbb X,q,\Sigma^*_i)+\log(\det(\Sigma^*_i)),$$
where $\|\cdot\|_{\Sigma}$ denotes the $\Sigma$-Mahalanobis norm, that is defined for $x\in\mathbb{R}^d$ by $\|x\|^2_{\Sigma}=x^T\Sigma^{-1}x$, $m(x,\mathbb X,q,\Sigma)=\frac1q\sum_{i=1}^qX^{(i)}$, where $X^{(1)},X^{(2)},\ldots,X^{(q)}$ are the $q$ nearest neigbours of $x$ in $\mathbb X$ for the $\|\cdot\|_{\Sigma}$-norm. Moreover, the local variance at $x$ for the $\|\cdot\|_{\Sigma}$-norm is defined by $v(x,\mathbb X,q,\Sigma)=\frac1q\sum_{i=1}^q\|X^{(i)}-m(x,\mathbb X,q,\Sigma)\|^2_{\Sigma}$.
These centers and covariances matrices are chosen such that the criterion $$R':(c_1,c_2,\ldots,c_k,\Sigma_1,\Sigma_2,\ldots,\Sigma_k)\mapsto\sum_{X\in\mathbb{X}}\min_{i\in\{1,2,\ldots,k\}}\|X-m(c_i,\mathbb X,q,\Sigma_i)\|_{\Sigma_i}^2+v(c_i,\mathbb X,q,\Sigma_i)+\log(\det(\Sigma_i))$$ is minimal.
The following algorithm provides local minimisers of the criterion $R'$.
from scipy.spatial import distance # For the Mahalanobis distance
def optima_for_kPLM(X,q,k,sig,iter_max = 10,nstart = 1):
'''
Compute local optimal centers and matrices for the k-PLM-criterion $R'$ for the point cloud X
Input:
X: an nxd numpy array representing n points in R^d
query_pts: an sxd numpy array of query points
q: parameter of the DTM in {1,2,...,n}
k: number of centers
sig: number of sample points that the algorithm keeps (the other ones are considered as outliers -- cf section "Detecting outliers")
iter_max : maximum number of iterations for the optimisation algorithm
nstart : number of starts for the optimisation algorithm
Output:
centers: a kxd numpy array contaning the optimal centers c^*_i computed by the algorithm
Sigma: a list of dxd numpy arrays containing the covariance matrices associated to the centers
means: a kxd numpy array containing the centers of ellipses that are the sublevels sets of the k-PLM
weights: a size k numpy array containing the weights associated to the means
colors: a size n numpy array containing the colors of the sample points in X
points in the same weighted Voronoi cell (with centers in means and weights in weights)
have the same color
cost: the mean, for the "sig" points X[j,] considered as signal, of their smallest weighted distance to a center in "centers"
that is, min_i\|X[j,]-means[i,]\|_{Sigma[i]^(-1)}^2+weights[i].
Example:
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
sig = X.shape[0] # There is no trimming, all sample points are assigned to a cluster
centers, Sigma, means, weights, colors, cost = optima_for_kPLM(X, 3, 2, sig)
'''
n = X.shape[0]
d = X.shape[1]
opt_cost = np.inf
opt_centers = np.zeros([k,d])
opt_Sigma = []
opt_means = np.zeros([k,d])
opt_weights = np.zeros(k)
opt_colors = np.zeros(n)
opt_kept_centers = np.zeros(k)
if(q<=0 or q>n):
raise AssertionError("Error: q should be in {1,2,...,n}")
elif(k<=0 or k>n):
raise AssertionError("Error: k should be in {1,2,...,n}")
else:
#kdt = KDTree(X, leaf_size=30, metric='euclidean')
for starts in range(nstart):
# Initialisation
colors = np.zeros(n)
kept_centers = np.ones((k), dtype=bool)
first_centers_ind = random.sample(range(n), k) # Indices of the centers from which the algorithm starts
centers = X[first_centers_ind,:]
old_centers = np.ones([k,d])*np.inf
Sigma = [np.identity(d)]*k
old_Sigma = np.copy(Sigma)
old_mi = np.zeros([k,d])
old_weights = np.zeros(k)
mi = np.zeros([k,d]) # means
vi = np.zeros(k) # variances for the mahalanobis norms
ci = np.zeros(k) # log(det(Sigma))
Nstep = 1
continue_Sigma = True
while((continue_Sigma or (np.sum(old_centers!=centers)>0)) and (Nstep <= iter_max)):
Nstep = Nstep + 1
# Step 1: Update mi, vi and ci
for i in range(k):
index = np.argsort([distance.mahalanobis(X[j,], centers[i,], np.linalg.inv(Sigma[i])) for j in range(X.shape[0])])
index = index[range(q)]
mi[i,] = np.mean(X[index,], axis = 0)
vect_aux = [distance.mahalanobis(X[index[j],], mi[i,], np.linalg.inv(Sigma[i])) for j in range(q)]
vi[i] = np.mean([val*val for val in vect_aux]) # The square of the Mahalanobis distance
sign, ci[i] = np.linalg.slogdet(Sigma[i]) # log(det(Sigma[i]))
# Step 2: Update colors and min_distance
min_distance = np.zeros(n) # Weighted distance between a point and its nearest center
for j in range(n):
cost = np.inf
best_ind = 0
for i in range(k):
if(kept_centers[i]):
aux = distance.mahalanobis(X[j,],mi[i,],np.linalg.inv(Sigma[i]))
newcost = aux*aux + vi[i] + ci[i]
if (newcost < cost):
cost = newcost
best_ind = i
colors[j] = best_ind
min_distance[j] = cost
# Step 3: Trimming step - Put color -1 to the (n-sig) points with largest cost
index = np.argsort(-min_distance)
colors[index[range(n-sig)]] = -1
ds = min_distance[index[range(n-sig,n)]]
costt = np.mean(ds)
# Step 4: Update Centers and mi and Sigma
old_centers = np.copy(centers)
old_mi = np.copy(mi)
old_weights = vi+ci
old_Sigma = np.copy(Sigma)
for i in range(k):
pointcloud_size = np.sum(colors == i)
if(pointcloud_size>1):
centers[i,] = np.mean(X[colors==i,],axis = 0)
index = np.argsort([distance.mahalanobis(X[j,], centers[i,], np.linalg.inv(Sigma[i])) for j in range(X.shape[0])])
index = index[range(q)]
mi[i,] = np.mean(X[index,], axis = 0)
aa = np.dot(np.array([mi[i,]-centers[i,]]).T,np.array([mi[i,]-centers[i,]]))
bb = (q-1)/q*np.cov(np.array([X[index[j],] for j in range(q)]).T)
cc = (pointcloud_size - 1)/(pointcloud_size)*np.cov(np.array(X[colors==i,]).T)
Sigma[i] = aa+bb+cc
elif(pointcloud_size==1):
centers[i,] = np.mean(X[colors==i,],axis = 0)
index = np.argsort([distance.mahalanobis(X[j,], centers[i,], np.linalg.inv(Sigma[i])) for j in range(X.shape[0])])
index = index[range(q)]
mi[i,] = np.mean(X[index,], axis = 0)
aa = np.dot(np.array([mi[i,]-centers[i,]]).T,np.array([mi[i,]-centers[i,]]))
bb = (q-1)/q*np.cov(np.array([X[index[j],] for j in range(q)]).T)
Sigma[i] = aa + bb
else:
kept_centers[i] = False
Stop_Sigma = True # True while old_Sigma = Sigma
for i in range(k):
if(kept_centers[i]):
Stop_Sigma = (Stop_Sigma and (np.sum([old_Sigma[i]!=Sigma[i]])==0))
continue_Sigma = not Stop_Sigma
if(costt <= opt_cost):
opt_cost = costt
opt_centers = np.copy(old_centers)
opt_means = np.copy(old_mi)
opt_weigths = np.copy(old_weights)
opt_Sigma = np.copy(old_Sigma)
opt_colors = np.copy(colors)
opt_kept_centers = np.copy(kept_centers)
centers = opt_centers[opt_kept_centers,]
Sigma = [opt_Sigma[i] for i in range(k) if opt_kept_centers[i]]#### ATTENTION !!!!
means = opt_means[opt_kept_centers,]
weights = opt_weigths[opt_kept_centers]
colors = np.zeros(n)
for i in range(n):
colors[i] = np.sum(opt_kept_centers[range(int(opt_colors[i]+1))])-1
cost = opt_cost
return(centers, Sigma, means, weights, colors, cost)
def kPLM(X,query_pts,q,k,sig,iter_max = 10,nstart = 1):
'''
Compute the values of the k-PDTM of the empirical measure of a point cloud X
Require sklearn.neighbors.KDTree to search nearest neighbors
Input:
X: a nxd numpy array representing n points in R^d
query_pts: a sxd numpy array of query points
q: parameter of the DTM in {1,2,...,n}
k: number of centers
sig: number of points considered as signal in the sample (other signal points are trimmed)
Output:
kPDTM_result: a sx1 numpy array contaning the kPDTM of the
query points
Example:
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Q = np.array([[0,0],[5,5]])
kPLM_values = kPLM(X, Q, 3, 2,X.shape[0])
'''
n = X.shape[0]
if(q<=0 or q>n):
raise AssertionError("Error: q should be in {1,2,...,n}")
elif(k<=0 or k>n):
raise AssertionError("Error: k should be in {1,2,...,n}")
elif(X.shape[1]!=query_pts.shape[1]):
raise AssertionError("Error: X and query_pts should contain points with the same number of coordinates.")
else:
centers, Sigma, means, weights, colors, cost = optima_for_kPLM(X,q,k,sig,iter_max = iter_max,nstart = nstart)
kPLM_result = np.zeros(query_pts.shape[0])
for i in range(query_pts.shape[0]):
kPLM_result[i] = np.inf
for j in range(means.shape[0]):
aux0 = distance.mahalanobis(query_pts[i,],means[j,],np.linalg.inv(Sigma[j]))
aux = aux0*aux0 + weights[j] # We don't take the squareroot, since aux could be negative
if(aux<kPLM_result[i]):
kPLM_result[i] = aux
return(kPLM_result, centers, Sigma, means, weights, colors, cost)
We compute the $k$-PLM on the same sample of points.
The sub-level sets of the $k$-PLM are unions of $k$ ellispoids which centers are represented by triangles.
' Compute the k-PLM on X '
# compute the values of the DTM of parameter q
q = 40
k = 250
sig = X.shape[0]
iter_max = 10
nstart = 1
kPLM_values, centers, Sigma, means, weights, colors, cost = kPLM(X,X,q,k,sig,iter_max,nstart)
# plot of the opposite of the DTM
fig, ax = plt.subplots()
plot = ax.scatter(X[:,0], X[:,1], c=-kPLM_values)
fig.colorbar(plot)
for i in range(means.shape[0]):
ax.scatter(means[i,0],means[i,1],c = "black",marker = "^")
ax.axis('equal')
ax.set_title('Values of -kPLM on X with parameter q='+str(q)+' and k='+str(k)+'.');

Detecting outliers - Trimmed versions of the $k$-PDTM and the $k$-PLM¶
The criterions $R$ and $R'$ are of the form $\sum_{X\in\mathbb{X}}\min_{i\in\{1,2,\ldots,k\}}\gamma(X,\theta_i)$ for some cost function $\gamma$ and some parameters $\theta_i$ ($c_i$ or $(c_i,\Sigma_i)$). Morally, points $X$ for which $\min_{i\in\{1,2,\ldots,k\}}\gamma(X,\theta_i)$ is small are close to the optimal centers, and then should be close to the compact set $\mathcal{K}$. Then, points $X$ such that $\min_{i\in\{1,2,\ldots,k\}}\gamma(X,\theta_i)$ is large should be considered as outliers, and should be removed from the sample of points $\mathbb X$.
Selecting $o\leq n$ outliers together with computing optimal centers is possible. Such a procedure is called trimming. It consists is finding $(\theta^*_1,\theta^*_2,\ldots,\theta^*_k)$ that minimise the criterion $$ (\theta_1,\theta_2,\ldots,\theta_k)\mapsto\inf_{\mathbb{X}'\subset\mathbb{X}\mid\left|\mathbb{X}'\right|=o}\sum_{X\in\mathbb{X}'}\min_{i\in\{1,2,\ldots,k\}}\gamma(X,\theta_i). $$ The elements of the optimal set $\mathbb X'$ should be considered as signal points, the remaining ones as outliers. The trimmed versions of the $k$-PDTM and the $k$-PLM follow.
The $o = n-sig$ outliers are represented in red in the following figures.
' Compute the trimmed k-PDTM on X '
# compute the values of the k-PDTM of parameter q
q = 5
k = 100
sig = 150 # Amount of signal points - We will remove o = 250 - 150 points from the sample
iter_max = 100
nstart = 10
kPDTM_values, centers, means, variances, colors, cost = kPDTM(X,X,q,k,sig,iter_max,nstart)
# plot of the opposite of the k-PDTM
fig, ax = plt.subplots()
plot = ax.scatter(X[:,0], X[:,1], c=-kPDTM_values)
fig.colorbar(plot)
for i in range(means.shape[0]):
ax.scatter(means[i,0],means[i,1],c = "black",marker = "^")
for j in range(X.shape[0]):
if (colors[j]==-1):
ax.scatter(X[j,0], X[j,1], c="red")
ax.axis('equal')
ax.set_title('Values of -kPDTM on X with parameter q='+str(q)+' and k='+str(k)+'.');

' Compute the trimmed k-PLM on X '
# compute the values of the k-PLM of parameter q
q = 10
k = 100
sig = 150
iter_max = 10
nstart = 1
kPLM_values, centers, Sigma, means, weights, colors, cost = kPLM(X,X,q,k,sig,iter_max,nstart)
# plot of the opposite of the k-PLM
fig, ax = plt.subplots()
plot = ax.scatter(X[:,0], X[:,1], c=-kPLM_values)
fig.colorbar(plot)
for i in range(means.shape[0]):
ax.scatter(means[i,0],means[i,1],c = "black",marker = "^")
for j in range(X.shape[0]):
if (colors[j]==-1):
ax.scatter(X[j,0], X[j,1], c="red")
ax.axis('equal')
ax.set_title('Values of -kPLM on X with parameter q='+str(q)+' and k='+str(k)+'.');

The sublevel sets¶
Functions to plot ellipsoids and disks¶
import math
import matplotlib
def Trace_ellipses(Sigma,center,alpha):
w, v = np.linalg.eig(Sigma)
index = np.argsort(-abs(w))
return(matplotlib.patches.Ellipse(center, 2*np.sqrt(alpha*w[index[0]]), 2*np.sqrt(alpha*w[index[1]]), angle= -180/math.pi*np.sign(v[index[0]][1])*math.acos(v[index[0]][0])))
def Trace_balls(center,alpha):
return(matplotlib.patches.Circle(center, np.sqrt(alpha)))
Sublevel sets of the $k$-PDTM¶
' Compute the sublevel sets of the k-PDTM on X '
q = 5
k = 100
sig = 150
iter_max = 10
nstart = 1
kPDTM_values, centers, means, variances, colors, cost = kPDTM(X,X,q,k,sig,iter_max,nstart)
# plot of the opposite of the k-PDTM
fig, ax = plt.subplots()
plot = ax.scatter(X[:,0], X[:,1], c=-kPDTM_values)
fig.colorbar(plot)
alpha = 0.2 # Level for the sub-level set of the k-PLM
Circle = [Trace_balls(means[i,],max(0,alpha*alpha - variances[i])) for i in range(means.shape[0])]
for cir in Circle:
ax.add_artist(cir)
cir.set_alpha(0.3) # For transparency
cir.set_facecolor("black")
for i in range(means.shape[0]):
ax.scatter(means[i,0],means[i,1],c = "black",marker = "^")
ax.axis('equal')
ax.set_title('Sublevel sets of the kPDTM on X with parameters q='+str(q)+' and k='+str(k)+'.');

Sublevel sets of the $k$-PLM¶
' Compute the sublevel sets of the k-PLM on X '
q = 10
k = 100
sig = 150
iter_max = 10
nstart = 1
kPLM_values, centers, Sigma, means, weights, colors, cost = kPLM(X,X,q,k,sig,iter_max,nstart)
# plot of the opposite of the k-PLM
fig, ax = plt.subplots()
plot = ax.scatter(X[:,0], X[:,1], c=-kPLM_values)
fig.colorbar(plot)
alpha = 10 # Level for the sub-level set of the k-PLM
Ellipses = [Trace_ellipses(Sigma[i],means[i,],max(0,alpha - weights[i])) for i in range(means.shape[0])]
for ell in Ellipses:
ax.add_artist(ell)
ell.set_alpha(0.3) # For transparency
ell.set_facecolor("black")
for i in range(means.shape[0]):
ax.scatter(means[i,0],means[i,1],c = "black",marker = "^")
ax.axis('equal')
ax.set_title('Sublevel sets of the kPLM on X with parameters q='+str(q)+' and k='+str(k)+'.');

References :¶
- [Brecheteau19a] Claire Brécheteau and Clément Levrard, “A k-points-based distance for robust geometric inference”. (2019++) Unpublished
- [Brecheteau19b] Claire Brécheteau, “Robust shape inference from a sparse approximation of the Gaussian trimmed loglikelihood”. (2019++) Unpublished
- [Chazal11] Frédéric Chazal, David Cohen-Steiner and Quentin Mérigot, “Geometric inference for probability measures”. In: Found. Comput. Math. 11.6 (2011), pp. 733–751.